
2024 sera une année électorale importante au niveau planétaire. En effet, une 40e de pays organiseront des élections l’année prochaine. Plus de 2 milliards de personnes se déplaceront dans les urnes aux USA, au Royaume-Uni, en Inde, en Indonésie, au Mexique, en Afrique du Sud, en Russie, à Taïwan et bien sûr en Europe avec les prochaines élections européennes ! Ce n’est donc pas surprenant que les inquiétudes concernant l’explosion des capacités à créer de la désinformation avec l’IA génératif – des chatbots aux deepfakes – augmentent, avec un risque réel de déstabilisation de nos démocraties et nos sociétés.
L’IA génératif peut quasi-instantanément cloner la voie d’un candidat, lui faire dire n’importe quoi dans un faux clip de campagne ou manipuler les messages et les narratifs. Nous en avons eu une illustration avec les dernières élections en Slovaquie perturbées par des deepfakes vidéos et audio, notamment sur facebook.
Dans cet article, je vous propose de revenir sur la définition même d’une deepfake, pourquoi son explosion, les techniques utilisées pour créer ces photos et vidéos truquées, les méthodes actuelles pour les détecter et les risques afférents.
Qu’est ce qu’une photo ou vidéo deepfake ?
Le deepfake (mot-valise provenant de Deep Learning et Fake), ou hypertrucage, est une technique de synthèse multimédia reposant sur l’Intelligence Artificielle. Cette technique permet de créer, fusionner, combiner, remplacer et superposer des images, vidéos, bande son, avec comme objectif de créer de faux contenus qui semblent authentiques.
Il s’agit notamment de la possibilité de créer du contenu humoristique, pornographique ou politique d’une personne énonçant un texte imaginaire; sans avoir le consentement de la personne dont l’image et la voix sont exploitées.
Depuis quelques années, nous assistons à une démocratisation de la technologie au travers de multiples applications permettant de réaliser des échanges de visages (face swap), de la synchronisation labiale (lip sync), de la génération de visages par l’IA (i.e. avatars), de l’imitation audio et stylistique.
Tous les supports multimédia sont aujourd’hui concernés par les deepfakes : vidéo, audio, simulation de messages textuels (type de typo, vitesse de frappe) et ont des objectifs variés :
- Harcèlement, vengeance ou chantage
- Pornographie par revanche (ou revenge porn)
- Falsification de preuves devant les tribunaux
- Sabotage politique
- Terrorisme et propagande
- Manipulation des marchés financiers
- Campagnes informationnelles
- […]
Ce sujet n’est pas nouveau. En effet, les chercheurs Jang et Kim dans leurs travaux en 2018 avaient déjà mis en évidence la nécessité de comprendre et de contrer les effets des fausses informations avec les risques de déstabilisation pour nos démocraties.
Les techniques utilisées pour créer les photos et vidéos deepfakes
Des principaux modèles d’apprentissage dits « génératifs »:
Initialement, les modèles d’apprentissages profonds permettaient d’effectuer des tâches de classification de contenu (qualifier, identifier, catégoriser le contenu d’une image ou vidéo). Ci-dessous un exemple de catégorisation utilisant un modèle de Computer Vision pour identifier des objets dans une image.
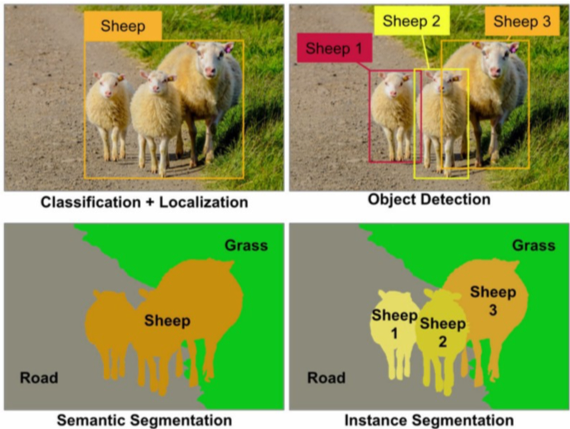
Ces dernières années ont vu apparaître des modèles génératifs particulièrement efficaces permettant la création de contenus riches et variés. On en compte aujourd’hui de très nombreux, dont les principaux:
L’auto-encodeur – Technique utilisée pour le face-swapping
Le face-swapping (ou échange de visage) est une des techniques utilisées pour créer des vidéos deepfakes. Elle se base sur l’utilisation d’un auto-encodeur, formé lui-même d’un encodeur et d’un décodeur.
L’encodeur décrit ce que la personne est en train de faire dans la vidéo et extrait les informations les plus importantes. De son côté, le décodeur va ensuite essayer de reconstruire l’image.
Pour simplifier, pensez à une scène de crime. L’encodeur serait le témoin décrivant la scène. Le décodeur serait la personne réalisant à partir de la description le portrait robot du suspect. Cela nécessite d’importantes bases d’images (de l’ordre de plusieurs 10e de milliers en entrée pour entrainer le modèle).

EDIT en Décembre 2023: Aujourd’hui une seule vidéo de 2min et un entrainement du modèle de quelques secondes permet d’obtenir un résultat similaire (voir ma vidéo ci-dessous).
Generative Adversarial Networks (GAN) – Le modèle avec le plus de potentiel
Les GAN, pour Generative Adversariale Networks (ou réseaux antagonistes génératifs) sont des modèles mathématiques qui permettent de générer des images avec un fort degré de réalisme.
De manière simplifié, le GAN est un ensemble de 2 réseaux de neurones qui collaborent: le générateur et le discriminateur. D’un côté, le générateur génère une image (d’où le modèle génératif). De l’autre côté, le discriminateur détermine si l’image produite par le générateur est réaliste ou non. Le discriminateur note les images produites par le générateur. Les images ayant les meilleures notes sont les plus réalistes et serviront à améliorer le modèle.
Pour prendre une image simplifier, imaginons un artiste peintre (le générateur) et un critique d’Art (le discriminateur). L’artiste tente la reproduction d’une œuvre, et le critique relève les différences entre la copie et l’originale. L’artiste tient compte du retour du critique et l’intègre pour améliorer sa copie. A mesure que la copie se rapproche de l’oeuvre copiée, l’artiste améliore sa copie jusque dans les moindres détails, ainsi que le critique d’Art qui doit également afiner ses critiques, jusqu’à arriver à une copie quasi parfaite.
La puissance des GANs réside donc dans l’auto-évaluation du modèle. Ce type de modèle est complexe à réaliser et nécessite un savoir-faire spécifique.
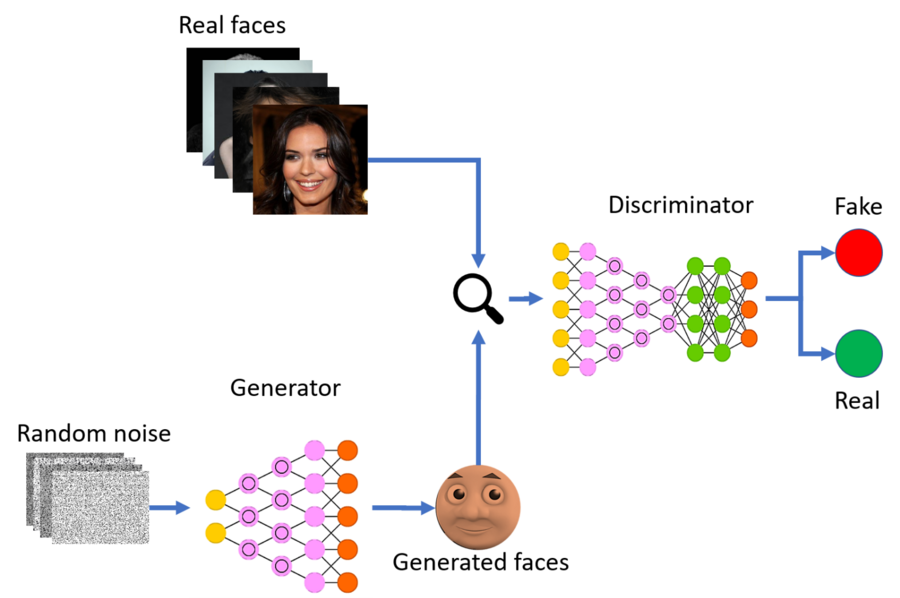
A noter que les dernières applications de text-to-image comme Midjourney utilisent une architecture modernisée des GAN, appelée GigaGAN. Cette architecture offre plusieurs avantages dont un temps de prédiction amélioré pour synthétiser une image et la possibilité de synthétiser des images en très haute résolution (et bien d’autres, que j’aurais pas la prétention d’exposer ici n’étant pas expert en GAN :).
Computer Vision – Technique utilisée pour les filtres Snapchat
Difficile de ne pas parler de Computer Vision et d’Image Processing, dont l’usage le plus connu est le filtre de Snapchat. Il s’agit tout d’abord de détecter les différentes zones du visage (face detection). Puis d’analyser ces mêmes zones comme le nez, les yeux, la bouche (facial landmarks). Enfin, il s’agit de proposer un traitement de l’image (image processing).

La même technique est utilisée par Facebook pour détecter votre visage dans les photos publiées sur la plateforme. Cette technique progresse également rapidement. Enfin, il semblerait que les derniers filtres snapchat utilisent maintenant du machine learning / cycleGAN pour toujours plus de réalisme.
La synthèse audio – Pour restituer la voix d’une personne
Au delà de l’image il faut également restituer fidèlement la voix d’une personne. D’importantes avancées ont été permises grâce au deep learning. Et il ne semble plus nécessaire d’avoir beaucoup de données pour entrainer le modèle audio. En 2019, Adobe indiquait qu’un extrait audio de 20min était maintenant suffisant pour générer une voix synthétique proche de la voix originale. (via son logiciel Adobe Voco, non distribué). EDIT: Aujourd’hui, fin 2023, les meilleurs logiciels de synthèse vocale permettent de reconstituer une voie avec seulement 3 secondes d’audio…
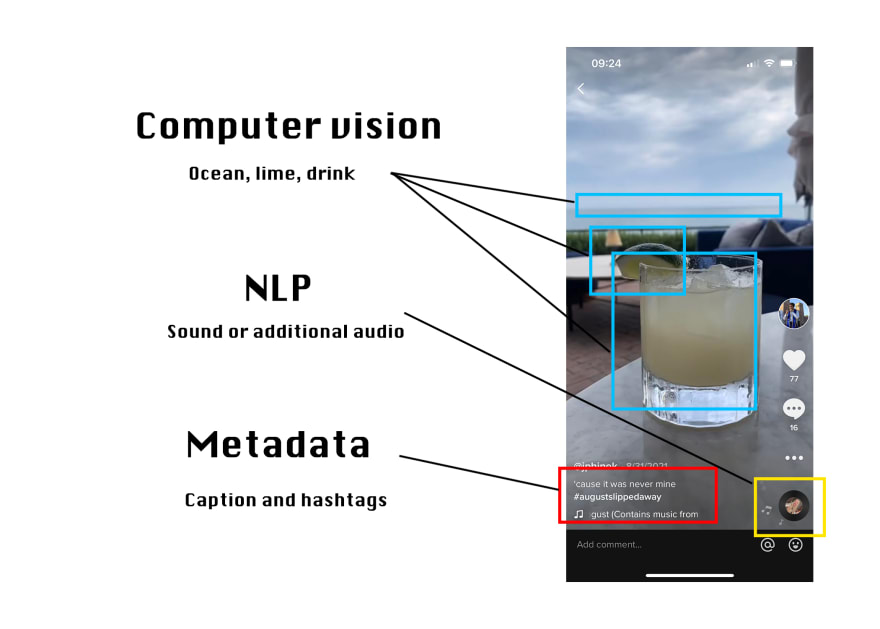
Affective computing & natural language processing (NLP)
Plusieurs études ont montré un lien entre la charge émotionnelle et la viralité d’un contenu. L’affective computing est un champ d’étude qui analyse, comprend et stimule les émotions humaines : clignement des yeux, transpiration, intensité du regard, phonologie, morphologie, syntaxe, sémantique, etc.
Pourquoi son développement? Les données nécessaire au développement du Natural Language Processing sont de plus en plus disponibles et accessibles. On estime à 10 000 expressions faciales (marqueurs) par humain, dont 4 000 sont signifiantes. Les marqueurs culturels peuvent être importants (un sourire japonais est différent d’un sourire européen).
On assiste également à une utilisation croisée de bases de données statiques vs. dynamiques, que l’on va pouvoir enrichir (collection des réactions par exemple par les applications des réseaux sociaux pour alimenter des bases de données dynamiques). Tiktok par exemple semble utiliser le Natural Language Processing, les metadonnées et du Machine Learning pour améliorer son outil de recommandation de vidéo.
Les deepfakes et la pornographie
Bien que l’impact des deepfakes sur les élections attire l’attention des médias, il y a un secteur qui a plus que les autres été impacté, la pornographie. Une étude citée par le Washington Post indique que 96% des images deepfakes sont des images pornographiques et que 99% de ces photos ciblent des femmes. L’une de mes intervenantes dans mon MBA en cybersécurité m’indiquait qu’environ la moitié des photos pédopornographiques utilisaient des photos d’enfants trouvées sur les réseaux sociaux. Elles sont également utilisées par les prédateurs pédopornographiques pour rentrer en contact avec d’autres enfants sur ces mêmes réseaux.
Parents, il est absolument impératif de mettre l’ensemble des comptes réseaux sociaux de vos enfants en mode privé. Suivez nos conseils pour protéger vos données numériques et celles de vos enfants. Et utilisez notre réglette pour anticiper et agir en cas de cyber-harcèlement dont pourrait être victimes vos enfants.
La quantité d’images et de vidéos pornographiques truquées sur les sites pornos a augmenté de manière exponentielle en 2023, cumulant des milliards de vues. Personne ne semble épargnée, des politiques aux célébrités, en passant par les jeunes adolescentes, le tout facilité par des applications de déshabillage. Le nombre de cas de collégiennes et lycéennes victimes de cyber-harcèlement (voir le film Another Body sortie en 2023, l’histoire vraie d’une étudiante américaine qui se retrouve du jour au lendemain sur un site porno) est en augmentation constante partout dans le monde. Et la situation ne devrait pas s’améliorer.
Création d’un avatar vidéo avec HeyGen
Les progrès technologiques sont hallucinant. Pour s’en rendre compte, j’ai testé l’application Heygen, qui autorise la création d’un avatar en 3D ainsi que le doublage d’une voie en multi-langues. Ci-dessous, un test que j’ai réalisé avec une de mes vidéos sources qui dure 2min seulement et qui sert à à l’apprentissage du modèle.
On arrête pas le progrès – L’entreprise Animate Anyone va bientôt permettre d’animer des personnages à partir d’une simple photo :
Comment identifier / détecter des photos et vidéos deepfakes ?
Il existe plusieurs méthodes de détection des photos et vidéos deepfakes, qui s’appuient sur le rendu final et sur des bases algorithmiques. Aucune n’est infaillible mais nous pouvons penser que là aussi, des progrès significatifs devraient être à l’œuvre, compte tenu des enjeux.
Voici donc ces méthodes pour détecter des photos et vidéos deepfakes:
- Discordance entre les phonèmes (son qui sort de la bouche) et les visèmes (mouvement des lèvres) (Agarwal, Farid, Fried, Agrawala, 2020)
- La désynchronisation du mouvement labial et le discours (Bitouk et al. 2008)
- L’analyse discriminante linéaire (LDA)
- La qualité d’image (IQM)
- Les machines à vecteurs de support (SVM) (Wen, Han & Jain, 2015 ; Galbally & Marcel 2014)
- Détection des fake news dans les réseaux sociaux. (Aldwairi & Alwahedi en 2018)
- Apprentissage automatique comportement différents (Durall et al. 2019)
- Combinaison de données de biométrie statique (Agarwal et al., 2020)
- Détecter d’anomalie d’un pixel (réseaux profonds) Guera et DElp, 2018 ;; Koopman, Rodrifuez & Geradts, 2018)
Identifier une vidéo deepfake à travers l’analyse de l’image
Certaines parties du visage humain générées artificiellement restent encore difficiles à truquer. C’est le cas pour les branches des lunettes (parties fines), les oreilles ou les doigts (parties complexes), l’alignement des dents ou des yeux, l’intérieur de la bouche et des narines. D’autres éléments comme l’absence ou l’irrégularité dans le clignement des yeux peuvent être un indicateur de deepfake.
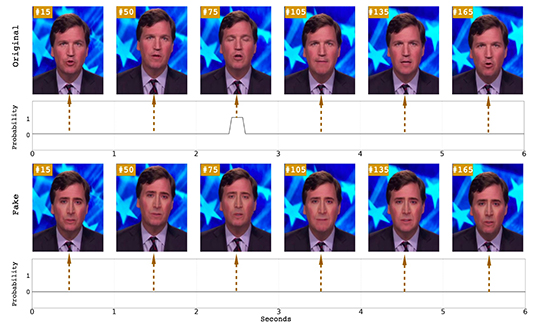
Certaines recherches, notamment menées par Hany Farid (spécialiste de la reconnaissance d’images, titulaire des Alfred P. Sloan & Guggenheim Fellowships) sont allées jusqu’à identifier l’absence d’afflux sanguins dans les vidéos deepfakes. En effet, les battements du cœur doivent normalement être visibles sur les vidéos originales. Les pixels de la peau devant se colorer de manière régulière.
Enfin, les bruits d’ambiance, inaudibles à l’oreille humaine (i.e. room tone) peuvent également aider à reconnaitre un fake audio.
Identifier une vidéo deepfake à travers ses métadonnées
Il est également possible d’utiliser les métadonnées d’une image pour savoir si elle a été truquée et détecter les modifications. Les métadonnées sont les informations numériques attachées à la vidéo comme la date ou les données GPS. Certains révélateurs apparaissent également lors de la chaine de traitement de l’image (correction couleur, dé-bruitage…). Le projet ipol.im s’intéresse notamment à ces révélateurs.
Identifier une vidéo deepfake via des analyses contextuelles
Pour des raisons évidentes, les médias s’intéressent de prêt à ses problématiques d’identification d’infox et deepfakes. L’Agence France Presse (AFP) a lancé plusieurs initiatives à travers son MediaLab comme InVid et WeVerify. Ces deux projets, accessibles au travers d’une extension de navigateur internet ont pour but de détecter si une image ou une vidéo a été truquée. Comment? En analysant les données pour remonter à la source d’origine. Dans quel but? Protéger la réputation des médias et vérifier les sources journalistiques pour éviter les propagations d’infox. L’objectif à terme est de mettre à disposition des professionnels et du grand public une base de données open source collaborative regroupant l’ensemble des contenus identifiés comme altérés ou faux.
Identifier une photo ou vidéo deepfake en OSINT
En Open Source Intelligence (OSINT), on ne fait pas d’analyse de pixel, mais plutôt de l’horodatage, pour confirmer le lieu (en fonction des conditions météo par exemple, comparaison avec des images satellites, analyse des vêtements dans leur époque, …). Le groupe OSINT pourra alors indiquer les éléments qui peuvent être confirmés par anyse et ceux qui ne le peuvent pas. Le groupe indiquera alors les outils utilisés (très souvent en open source) et la communauté pourra ainsi confirmer la méthode. Cela permet la reproductibilité de l’analyse. Voir le plugin de vérification de WeVerify.
Assurer la traçabilité d’une vidéo à travers la blockchain
Demain, nous assisterons au marquage de vidéos via watermark (marqueur numérique) afin d’en certifier l’origine. La traçabilité pourra se faire via des technologies de blockchains. Un peu à la manière de ce que proposent Louis Vuitton pour assurer la traçabilité de ces produits de luxe.
D’autres projets sont en cours d’études, comme le projet de logiciel intelligent Reality Defender de l’AI Foundation. Ce logiciel, disponible à travers une extension internet scanne les images et vidéos à la recherche d’éventuelles modifications. On notera également l’initiative lancée par deux chercheurs de l’université de UC Berkley autour d’une méthode analysant le mouvement des lèvres « lip-sync ».

Autres outils et solutions pour détécter les deepfakes
La menace de déstabilisation par deepfake étant de plus en plus présente, des organisation publiques et privées ont investi pour combattre cette problématique. Parmi les acteurs (je n’ai pas testé leurs solutions), on notera la solution de Sentinel qui permet de téléverser un media et avoir un rapport sur la véracité du contenu, avec les manipulations opérées en cas de fake. Intel a lancé un détecteur de deepfake en temps réel nommé FakeCatcher.
Utilisation de deepfakes dans le conflit Russie – Ukraine
Il est intéressant de noter par exemple que peu de deepfakes ont été utilisés dans le cadre du conflit Ukraine – Russie, avec seulement 2 clairement identifiées. Cependant, nous avons vu dans cette même guerre de la désinformation l’utilisation de vraies photos de charniers mais provenant d’autres conflits.
La limite des outils de détection de deepfakes actuellement
Les méthodes qui marchent le mieux aujourd’hui sont à tempérées car sont fortement dépendantes de la qualité de la vidéo analysée (une vidéo HD fonctionne mieux qu’une vidéo disponible en faible résolution). Une deepfake pourrait utiliser une qualité de vidéo volontairement dégradée (pour simuler une vidéo « live ») et serait alors difficilement détectable par les outils de détection.
De plus, la vitesse et la viralité avec laquelle les fausses informations sont partagées rendent toute opération corrective plus complexe à mettre en œuvre, car pendant que les outils de vérifications opèrent, la vidéo ou photo deepfake aura déjà été partagée des milliers ou des millions de fois. Avec malheureusement un contenu véritable qui n’aura pas le même succès en terme d’audience.
QUID de la responsabilité des plateformes d’hébergement
Les plateformes d’hébergement (qui ne sont toujours pas considérées comme des plateformes d’édition et qui auraient donc une responsabilité sur le contenu), sont des entreprises qui font du business: le maximum de gens, viennent, interagissent, ceci afin de vendre de la pub. Les vidéos sensationnelles, provocantes, clivantes, feront malheureusement toujours plus de vues car recevront plus d’engagements des internautes.
Voir notre infographie sur la face cachée des réseaux sociaux
Sans parler de la difficulté croissance à distinguer une véritable image d’une scène de guerre versus une séquence de jeu vidéo de plus en plus réaliste. Il devient plus que jamais nécessaire de développer son esprit critique et de bien réfléchir avant de cliquer sur partager / liker une photo ou une vidéo !
Merci à mon intervenante chercheuse qui est intervenue dans le cadre de mon MBA Cybersécurité pour le partage des fondements théoriques en lien avec la recherche sur les deepfakes, , et qui m’ont permis d’enrichir cet article.
Laisser un commentaire